There are only two hard things in Computer Science: cache invalidation and naming things.
– Phil Karlton
LRU的实现
正如文章开头引用所说的那样,缓存失效被一些人(可能是大多数人)当成计算机两大难题之一,这说明了缓存的重要性,将最近的或经常使用的数据项保存在缓存中可以提高性能。当缓存满时,需要缓存替换算法(或者缓存替换策略)选择丢弃一些项目,从而为新项目腾出空间。
缓存的淘汰策略
多达20种左右,我们今天的主角–LRU ,就是其中之一,翻译过来是最近最少使用,也就是把最久没有被访问到的数据淘汰掉。它基于一个假设:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。
我们来看看如何实现一个高效的LRU缓存。
LRU缓存是由两个数据结构组成:一个双向链表和一个哈希表,如果你比较了解Java的话,差不多可以认为是LinkedHashMap
。大概是这样:
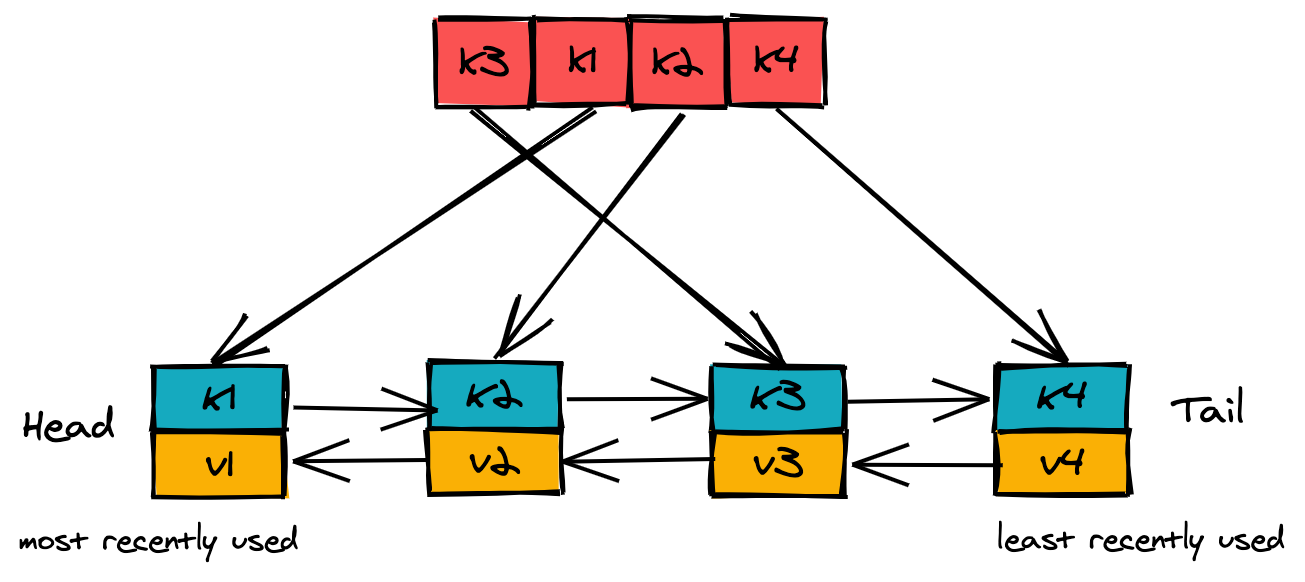
上边是一个hashMap,下边是一个双向链表,有了这个数据结构,我们来看看怎么使用。
get
- 在hashMap中查找这个项目
- 如果该项目在hashMap中,则我们已经缓存这个数据了,称为”cache hit”
- 利用hashMap快速找到对应的链表节点
- 将项目的链表节点移到链接列表的头部,因为它现在变成了最近使用的
- 如果该项目不在hashMap中,则”cache miss",返回null
put
- 在hashMap中查找这个项目
- 如果该项目在hashMap中,更新value并将链表中对应的节点移到头部
- 如果该项目不在hashMap中
- 如果缓存满了,我们需要淘汰一些项目来腾出空间
- 找到缓存中使用频率最低的项目,即链接列表的尾节点
- 从链表和hashMap中删除该项目
- 为该项目创建一个新的链表节点,将其插入到链表的头部
- 将该项目添加到我们的hashMap中(将新创建的链表节点作为值)
这些步骤都是O(1)的操作,所以综合起来也是O(1)的。
由于在淘汰数据的时候,需要将其从链表和hashMap中都删掉,所以在链表中我们也要把key存下来。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
import java.util.HashSet;
import java.util.LinkedList;
class CacheEntity {
int key;
int value;
public CacheEntity(int key, int value) {
this.key = key;
this.value = value;
}
}
class LRUCache {
private int capacity;
private LinkedList<CacheEntity> linkedList;
private Map<Integer, CacheEntity> hashMap;
public LRUCache(int capacity) {
this.capacity = capacity;
this.linkedList = new LinkedList<CacheEntity>();
this.hashMap = new HashMap<Integer, CacheEntity>();
}
public int get(int key) {
CacheEntity entity = this.hashMap.get(key);
if (entity == null) return -1;
moveToHead(entity);
return entity.value;
}
public void put(int key, int value) {
CacheEntity entity = this.hashMap.get(key);
if (entity != null) {
entity.value = value;
moveToHead(entity);
return;
}
if (this.hashMap.size() >= this.capacity) evictEntity();
entity = new CacheEntity(key, value);
this.linkedList.addFirst(entity);
this.hashMap.put(key, entity);
}
private void moveToHead(CacheEntity entity) {
this.linkedList.remove(entity);
this.linkedList.addFirst(entity);
}
private void evictEntity() {
CacheEntity entity = this.linkedList.removeLast();
this.hashMap.remove(entity.key);
}
}
public class Main {
public static void main(String[] args) {
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // cache is {1=1}
lRUCache.put(2, 2); // cache is {1=1, 2=2}
lRUCache.get(1); // return 1
lRUCache.put(3, 3); // LRU key was 2, evicts key 2, cache is {1=1, 3=3}
lRUCache.get(2); // returns -1 (not found)
lRUCache.put(4, 4); // LRU key was 1, evicts key 1, cache is {4=4, 3=3}
lRUCache.get(1); // return -1 (not found)
lRUCache.get(3); // return 3
lRUCache.get(4); // return 4
}
}
|
注意,上边的代码中直接使用了Java的LinkedList,导致从链表中删除一个节点的时间变成了O(n),这块可以优化,具体方式是自己维护一个链表,通过直接操作被删除节点的左右节点来进行删除操作,有兴趣的可以自己试试。
LRU在Redis中的应用
既然是缓存淘汰策略,LRU在Redis中自然是被应用了的,来复习一下Redis的缓存淘汰策略:
| 策略 |
描述 |
| noeviction |
不删除策略, 达到最大内存限制时, 如果需要更多内存, 直接返回错误信息。 大多数写命令都会导致占用更多的内存(有极少数会例外, 如 DEL ) |
| allkeys-lru |
所有key通用; 优先删除最近最少使用(less recently used, LRU) 的 key |
| allkeys-lfu |
所有key通用; 优先删除使用频率最低(Least frequently used, LFU) 的 key |
| allkeys-random |
所有key通用; 随机删除一部分 key |
| volatile-lru |
只限于设置了expire的key; 优先删除最近最少使用(less recently used, LRU) 的 key |
| volatile-lfu |
只限于设置了expire的key; 优先删除使用频率最低(less recently used, LRU) 的 key |
| volatile-random |
只限于设置了expire的key; 随机删除一部分 key |
| volatile-ttl |
只限于设置了 expire 的部分; 优先删除剩余时间(time to live,TTL) 短的key |
可以看到这里有两个lru策略:allkeys-lru和volatile-lru。需要注意的是为了节省内存,Redis并没有采用精确的LRU,而是利用样本来近似实现LRU策略,样本可以通过maxmemory-samples设置,详细信息可以参考Redis: lru-cache
。
文章作者
杂毛小道
上次更新
2021-01-19
许可协议
署名 4.0 国际 (CC BY 4.0)