
SnowFlake 算法是 Twitter 开源的分布式ID生成算法,它用·命名空间分区的方式将64个bits分成几个部分,每个部分代表不同的含义,且ID引入了时间戳,基本上是保持自增的。
64位整数在Java中是Long类型,所以SnowFlake算法在Java中生成的ID是存储成long的。
SnowFlake将64个bits分成4部分:
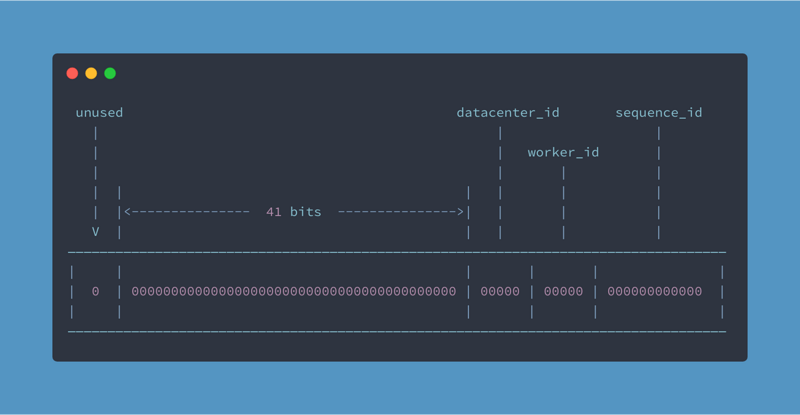
- 第一部分占1bit,其值始终为0,可视为符号位未使用(因为二进制里第一个 bit 为如果是 1,则变成了负数)。
- 第二部分占41bits,表示时间戳,共有
2^41个数字,单位是毫秒,则雪花算法可用的时间为(1L < 41)/(1000L * 3600 * 24 * 365)(约69)年。
- 第三部分占10bits,表示机器ID,共能表示
2 ^ 10 = 1024台机器,但一般情况下我们是不会这样部署机器的。我们可能需要IDC(Internet Data Center),所以一般将这10bits分成两部分,比如给IDC分5 bits,给工作机器分5bits。这样就可以表示32个IDC,每个IDC可以有32台机器,具体分区可以根据自己的需要来定义。
- 第四部分占12bits,是一个自增序列,可以表示
2^12=4096个数。
这样的分区相当于可以在一毫秒内在某一个数据中心的某一台机器上生成4096个有序的、不重复的ID。
思路还是很简单的,直接上代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
|
public class SnowflakeDistributeId {
/**
* 时间初始值(大概能用69年)
*/
private final long snowEpoch = 1420041688888L;
/**
* 机器id占用的bits数量
*/
private final long workerIdBits = 5L;
/**
* IDC id占用的bits数量
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果为31(5位二进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大IDC id,结果为31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 最后的自增序列占12个bits
*/
private final long sequenceBits = 12L;
/**
* 机器id 需要向左移12bits
*/
private final long workerIdShift = sequenceBits;
/**
* IDC 需要向左移17bits
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间戳 需要向左移22位
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 序列掩码 (0b111111111111 = 0xfff = 4095)
* 用&运算保证sequence不会超过4095这个范围
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 机器 id (0-31)
*/
private long workerId;
/**
* IDC id (0-31)
*/
private long datacenterId;
/**
* 一毫秒内的序列值 (0-4095)
*/
private long sequence = 0L;
/**
* 最后一次生成ID的时间戳
*/
private long lastTimestamp = -1L;
public SnowflakeDistributeId(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 生成下一个id
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
// 如果当前时间小于上一个ID生成的时间戳,说明时间回拨了,直接抛异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
// 如果当前时间戳和上一个时间戳相同,说明在同一个毫秒内,则以毫秒为单位进行排序
if (lastTimestamp == timestamp) {
// 保证sequences小于4096,否则sequences为0,需要等下一毫秒
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else { // 时间戳已经变了,重置sequence为0
sequence = 0L;
}
lastTimestamp = timestamp;
// 组装整个id
return ((timestamp - snowEpoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得一个新的时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen() {
return System.currentTimeMillis();
}
}
public static void main(String[] args) {
SnowflakeDistributeId idWorker = new SnowflakeDistributeId(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(id);
}
}
|
回头看一下代码,有几点是需要注意的。
首先上边的实现中用了不少位运算,其中-1L ^ (-1L << n)是一个小技巧,用来快速计算n位二进制能表示最大的十进制数。
另外在第95行抛出的异常说明雪花算法对机器时钟的依赖性很强。如果机器上的时钟回拨,可能会生成重复的id。对于这个问题,官方并没有给出解决方法,而是直接抛出了错误,在时间回归正常之前的这段时间内,服务将无法使用。
文章作者
杂毛小道
上次更新
2021-01-26
许可协议
署名 4.0 国际 (CC BY 4.0)